How memory system works ?
How memory system works ?
本文用来梳理一些基础的 内存 相关的知识点,以自顶向下的方式(可能是?)来讲解一遍内存的工作方式。会涉及到 Virtual Memory,Main Memory → Cache address mapping。
以一个小程序开头:
1 | int add(int a, int b){ |
我们看一下这段代码的汇编代码,在这里我们使用 -Og 指令来避免编译器的优化。
1 | 0000000000401550 <add>: |
可以看到,不管你使用什么操作来进行编译,这里的汇编代码对应的地址都是固定的。显然,汇编器输出了一个 逻辑地址 ,这个逻辑地址独立于 virtual address 和 physical address.
那么这些逻辑地址在程序运行阶段是怎么被 Loader 和 Linker 变换到正确的地址位置上的呢?我或许会再开一个深坑来讲讲,雾。我在这里使用这个例子,只是为了先给出地址的一个概念。并且让读者分清楚 汇编出来的 address 和 virtual address 和 physical address 是不同的。
Virtual Memory
上文中展示的汇编代码的逻辑地址会首先被翻译成 virtual address ,然后 virtual address 会被翻译成 physical address,然后在运行的过程中 physical address 会被 mapping 到对应的缓存结构中,也就是 Main Memory address → Cache 的过程,当然不一定是 Cache, 也可以是其他的缓存结构。
我们首先来看下定义:虚拟内存被组织为存放在磁盘上的N个连续字节大小的单元数组,每个字节都有一个唯一的虚拟地址,而该数组的内容被缓存在主存中。
Why we need virtual memory
使用一个统一的 Virtual memory address 可以使系统对硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的掌控更加的快捷和便利。使用虚拟内存可以为每一个进程提供一个非常大的、一致的地址空间。
上文说到,虚拟内存是有利于内核进程来管理自己的独立页表的,虚拟内催使每个进程都有自己的独立虚拟地址空间。如下面的这张图所示:
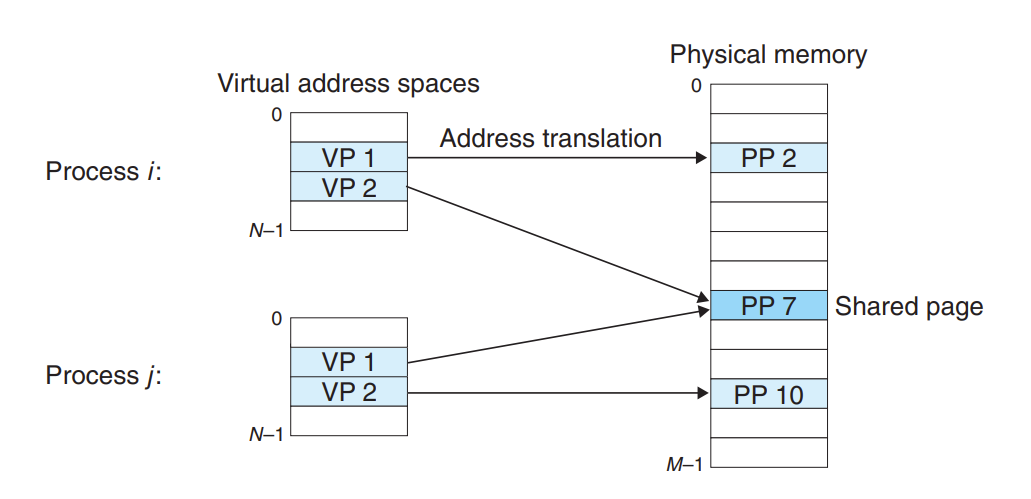
通过这种形式,我们可以提供一个视图:每个进程都有一个非常相似的虚拟地址空间,有着相同的大小的地址空间,而进程使用的物理页实际上可能使分散在 DRAM 中的。这样的组织形式,其实很大的程度上简化了 Linker 生成可执行文件时确定内存地址时候的麻烦。因为这种形式无须考虑当前的物理地址的内存状态,Linker 只需要假设一个虚拟的内存模型(如下图),链接好所有的地址后,由相关的系统命令和硬件把这些地址翻译成 physical address 就行了。
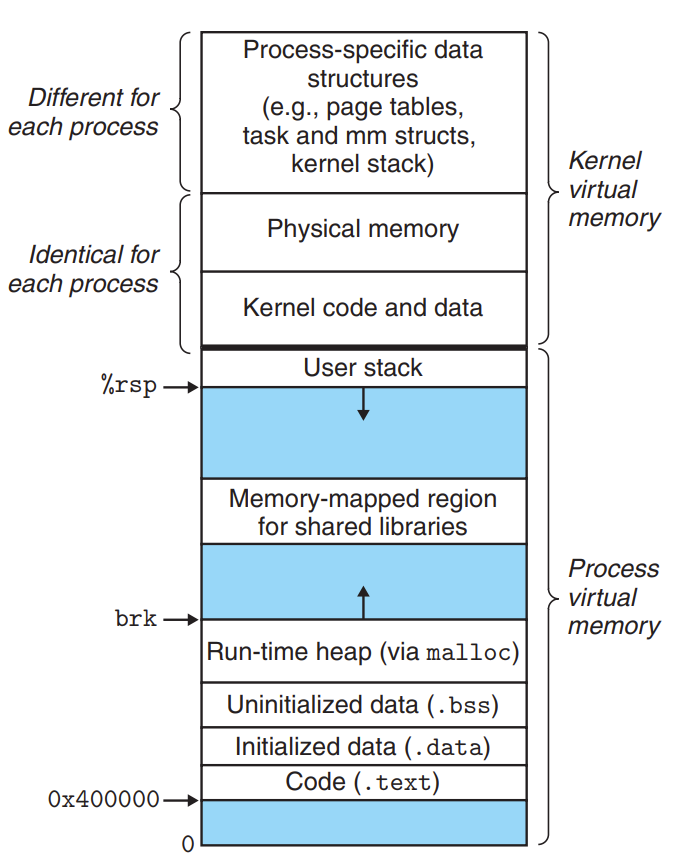
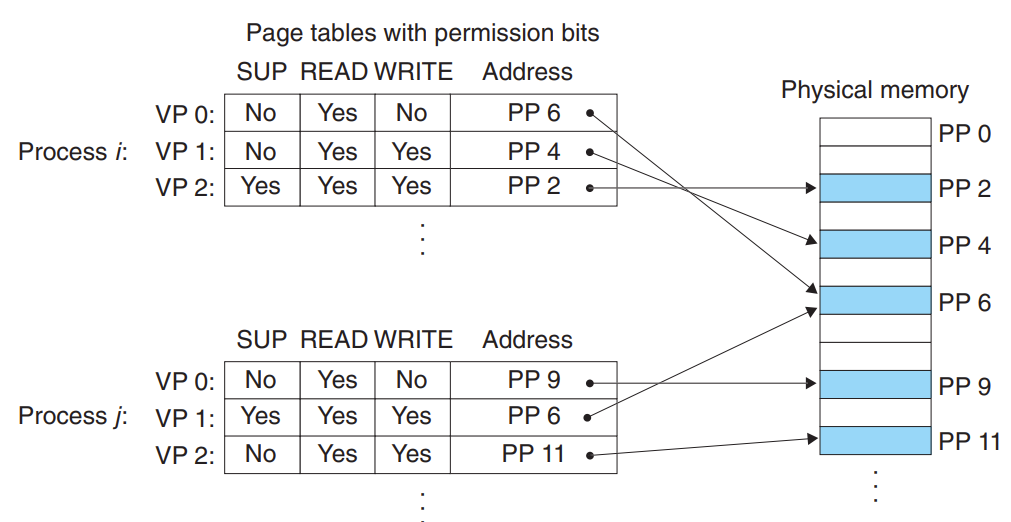
同时,虚拟内存还可以作为内存保护的工具,我们可以给每个虚拟的 page 加上几个 flags,比如 readable,writeable,user-state, kernel-state 来区分每个 process 对相应的实际内存中数据的处理权限。如下面这张图所示:
What is virtuall memory
在 Why use virtual memory 中实际已经提到过了:使用一个统一的 Virtual memory address 可以使系统对硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的掌控更加的快捷和便利。使用虚拟内存可以为每一个进程提供一个非常大的、一致的地址空间。
那么接下来就是看看 physical address(on disk)是怎么与 main memory 联系起来的,physical address 与 virtual address 是怎么转换的。
借用 CSAPP 的内容:

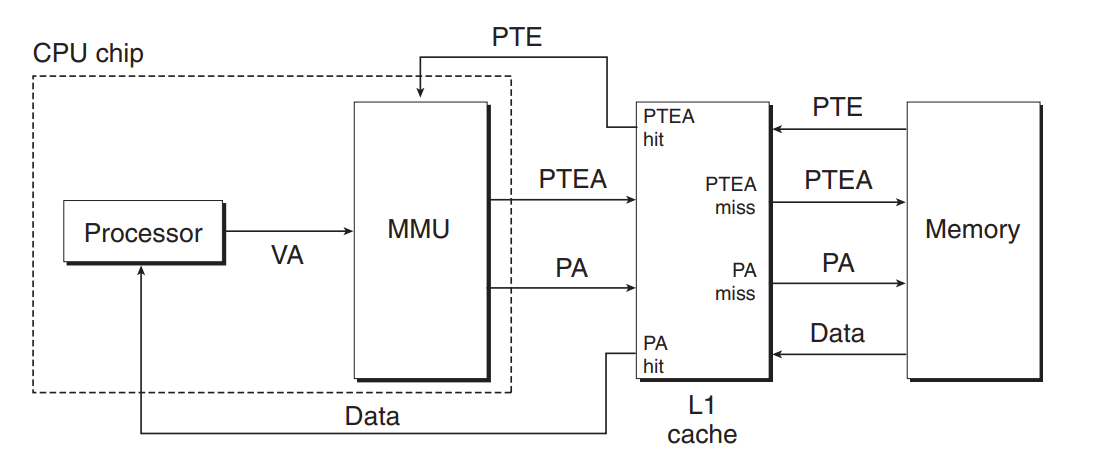
那么这个过程主要是通过 MMU(memory manage unit) 和 保存在 main memory 中的 PTE 来实现
MMU 具有下述结构:
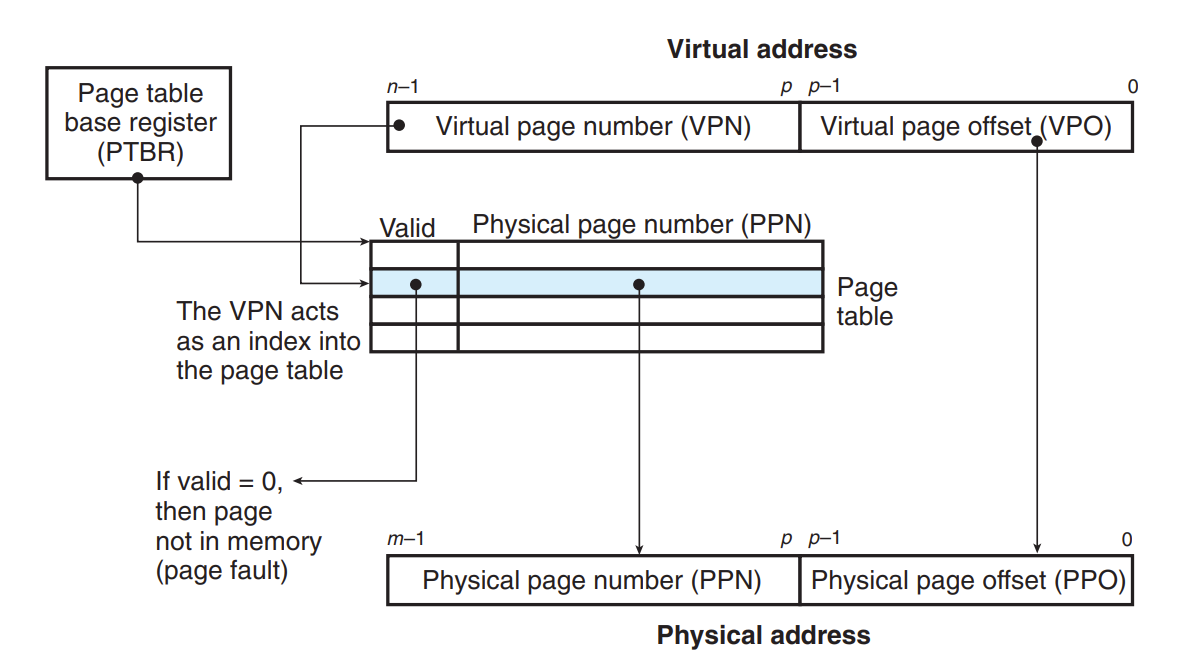
主要的地址寻找流程如下:
使用 TLB 来加速地址翻译:
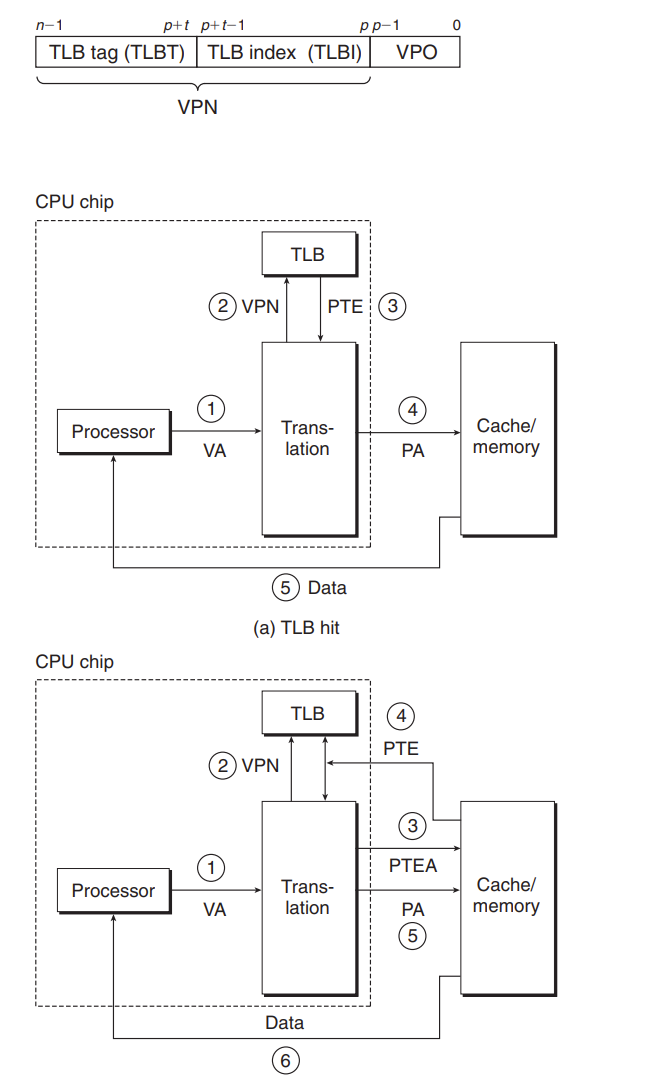
How to ue it
Main Memory address → Cache address
Conclution
Reference
[1] Computer system: A programmer’s perspective. 3ed
[2] Computer organization. Tang
How memory system works ?
https://chenghuawang.github.io/2022/04/16/How memory system works/